监督学习
监督学习是一种机器学习方法,它从标记的训练数据学习,以便能够预测未见过数据的标签。
在监督学习的训练集(training set)中,每个训练样本都包含输入特征(feature)和相应的输出标签(label)。

训练后的模型应该在输入训练集中的大多数特征时,都能够返回其正确的标签。
此后,可以用该模型根据特征对未知的标签进行预测。
房价预测
在不考虑地段、交通和其他因素的情况下,房价和房屋面积可以大致形成一个线性关系。
模型的训练集:
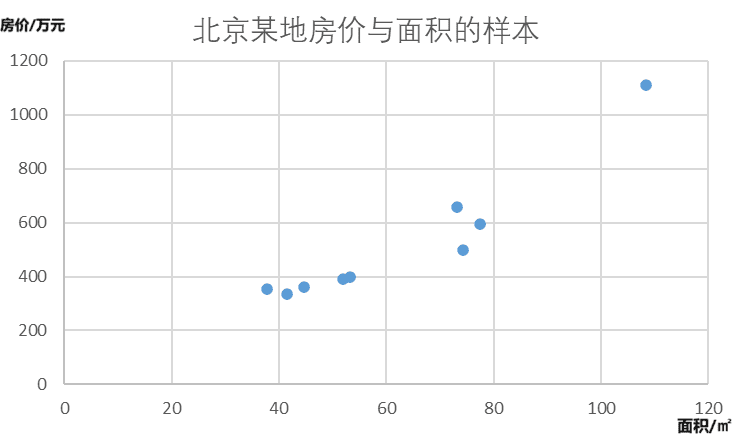
样本中每一个房屋面积都对应一个房价。
监督学习中的回归模型可以根据训练集生成算法,
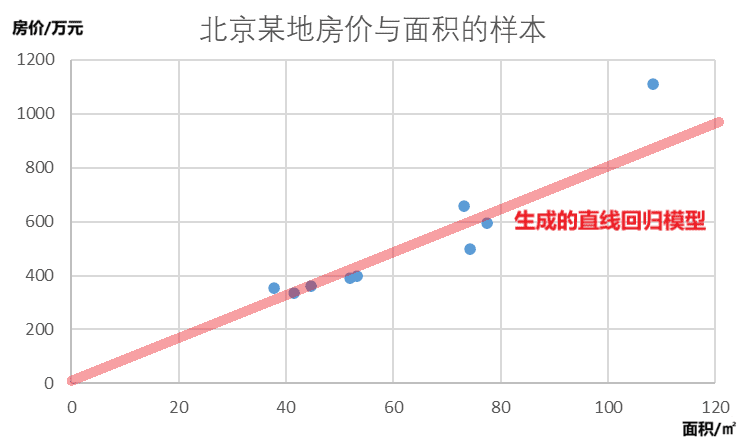
然后,可以利用该模型预测已知面积的房屋的售价。我们可以对面积为60平米的房屋价格进行预测,
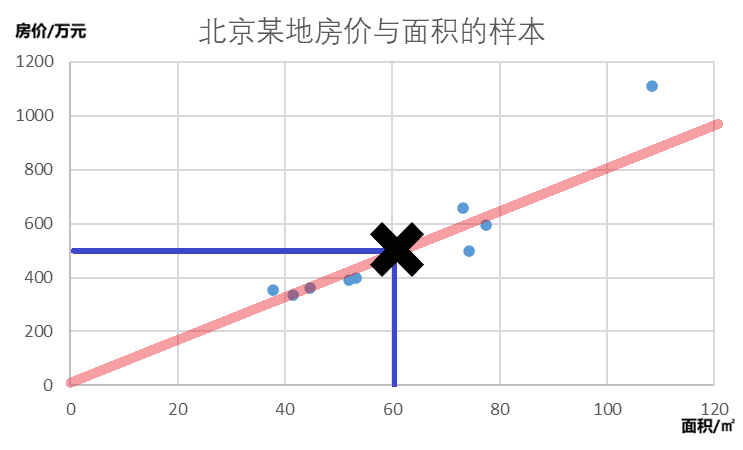
如图,在回归线上取面积为60平米的点,可以得到房屋的面积约为500。
辨别垃圾邮件

辨别垃圾邮件可以利用监督学习的分类模型。我们将垃圾邮件标记为‘1‘,其他邮件标记为‘0’。从而用训练后的模型辨别垃圾邮件。
为了简化这个问题,我们姑且将邮件标题的字数作为评定邮件是否为垃圾邮件的唯一特征。这在现实中极其不科学,但可以很好地阐释分类模型的作用。
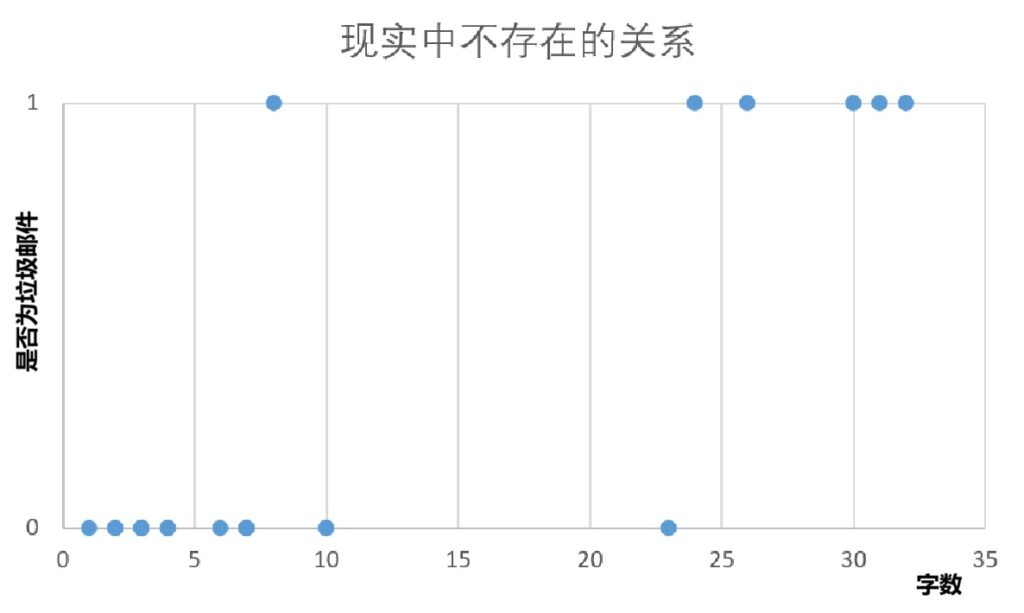
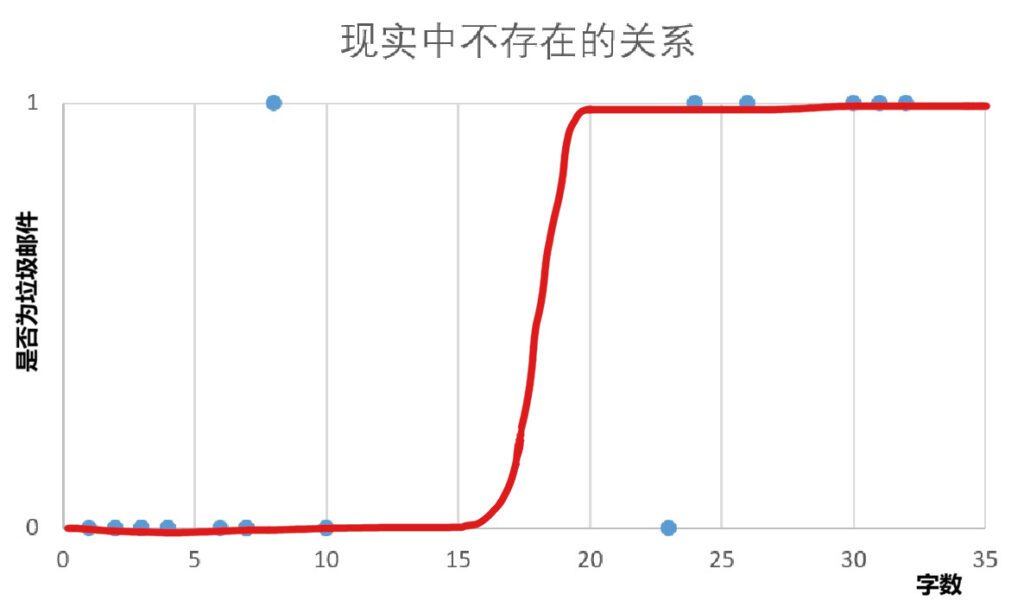
训练模型后,可以通过算法预测已知标题字数的邮件是否为垃圾邮件,
VztZoQaP0Hv
KMSl7umVsCK
UXgikU9hxoI
We enjoy reading your blog. The author always provide valuable information. Thanks for sharing.
It’s hard to find experienced people on this subject, however, you
sound like you know what you’re talking about!
Thanks
Well researched and educational; this post stands out.